Crawl Depth refers to how many subfolders a URL was encountered at from the entry-point URL that the crawl began.
Typically if you begin a crawl at the homepage the category pages & primary navigation level URLs will have a crawl depth of one, with subcategory pages being a 2 & so on.
It is important to note where you begin your crawls though, as calling for a crawl from a URL that is on level 2 will result in different results than from beginning a crawl from the homepage or one Level 1.
Understanding Website Crawl Depth Examples
When a crawl is initiated, a user inputs a URL that they want to use as a starting point.
From there, the crawler accesses all of the URLs that it finds linked from that URL & its template to collect all of the information it can on the overall domain & its pages.
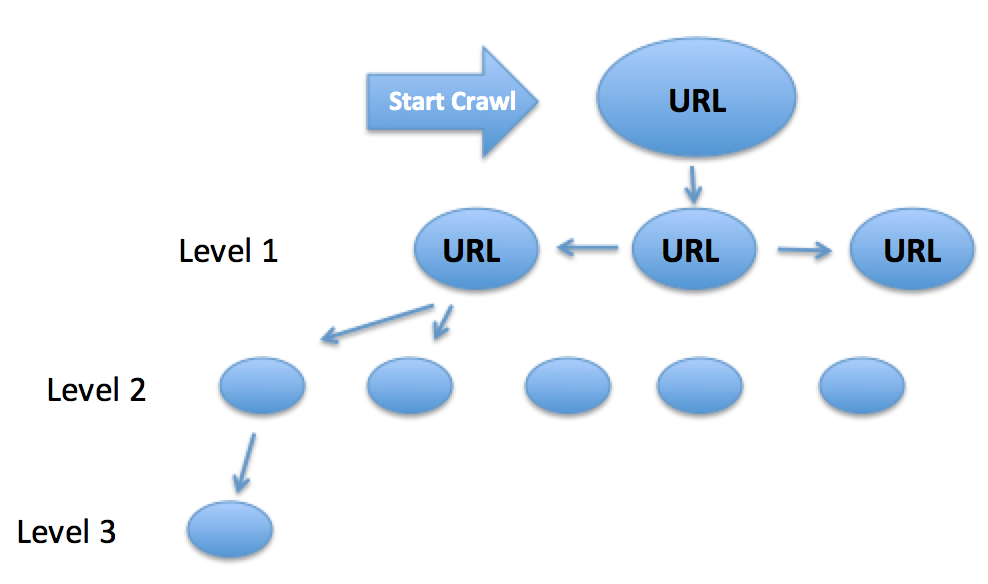
From the homepage, the category pages become Level 1, with SubCategory pages becoming Level 2, and the next directory of URLs being Level 3.
The URL structure would look like
Level 1: https://example.com
Level 2: https://example.com/fun-examples/
Level 3: https://example.com/fun-examples/not-this-one/
Let’s say that instead we queue up a crawl from one of the category pages.
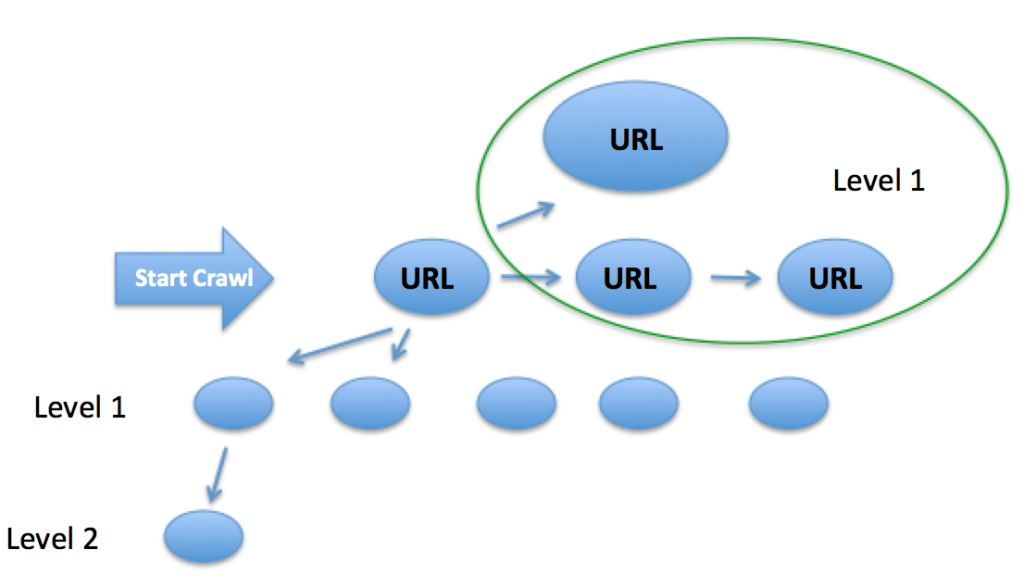
At this point, because the URLs are being encountered from the category level, the homepage & other category pages join Level 1.
The SubCategory pages are also on Level 1, as they are directly accessed from the entry point.
This makes the next directory level of pages moved up to Level 2 now, as they are found quicker from this entry point.
Understanding where your entry-points are in a crawl is essential, especially for sites with larger taxonomies.